Move over AlphaGo: AlphaZero taught itself to play three different games
Por um escritor misterioso
Descrição
DeepMind's new AI is worthy successor to the first program to beat a human at Go.

AlphaGo Zero Explained

AlphaZero: Shedding new light on chess, shogi, and Go - Google DeepMind
:focal(4290x2860:4291x2861)/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/filer/64/73/6473f6c7-4e17-40a2-a612-826f0084f709/m5af7m.jpg)
Google's New AI Is a Master of Games, but How Does It Compare to the Human Mind?, Innovation
Self-play reinforcement learning in AlphaGo Zero. a The program plays a

Artificial Intelligence Learns to Learn Entirely on Its Own

This More Powerful Version of AlphaGo Learns On Its Own
/cdn.vox-cdn.com/uploads/chorus_asset/file/13408501/computer_chess_getty_ringer_2.jpg)
AI Taught Itself to Be the Best Chess Player in the World—What's Next? - The Ringer
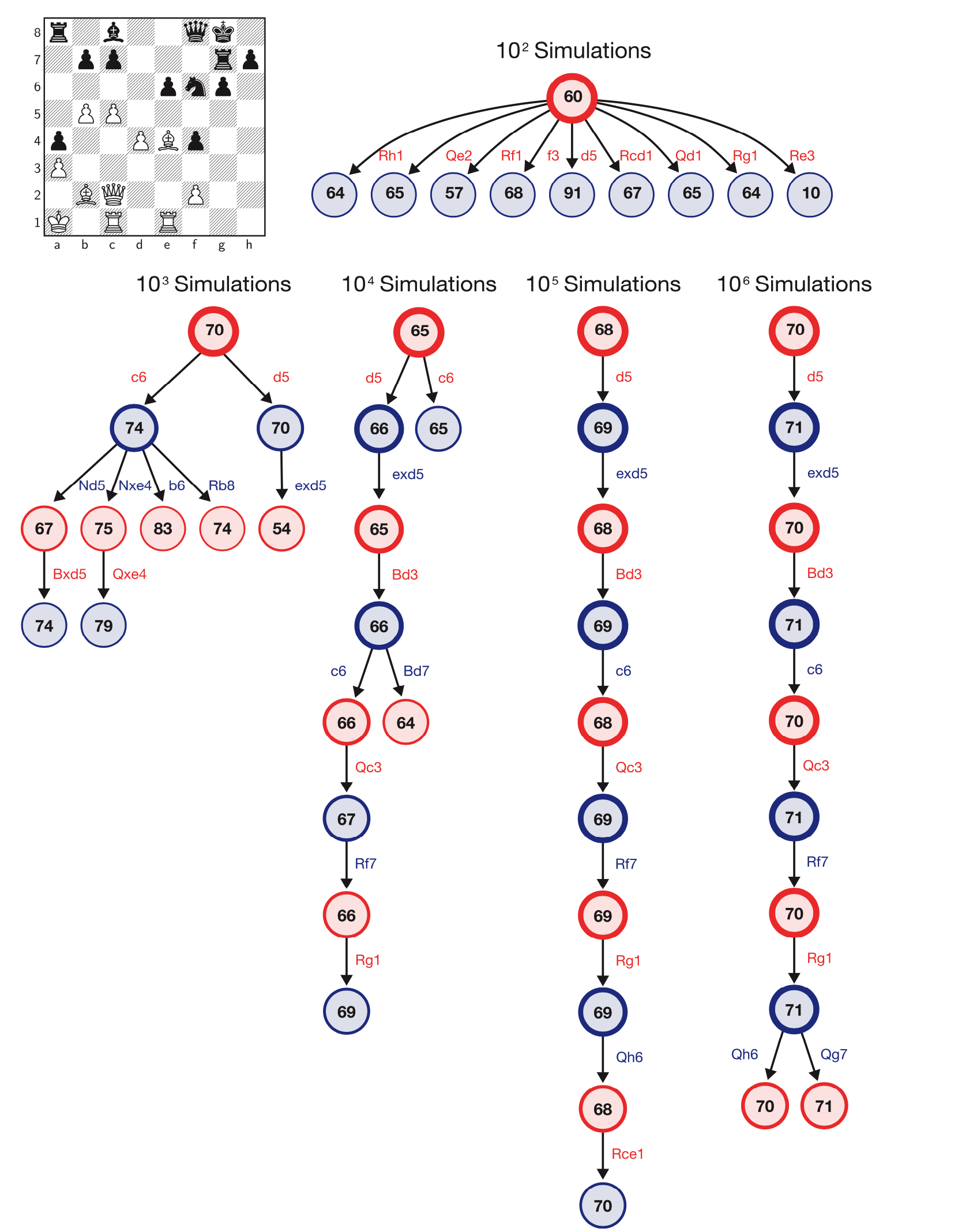
AlphaZero Crushes Stockfish In New 1,000-Game Match

AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community
Empirical evaluation of AlphaGo Zero. a Performance of self-play

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

It's able to create knowledge itself': Google unveils AI that learns on its own, Science
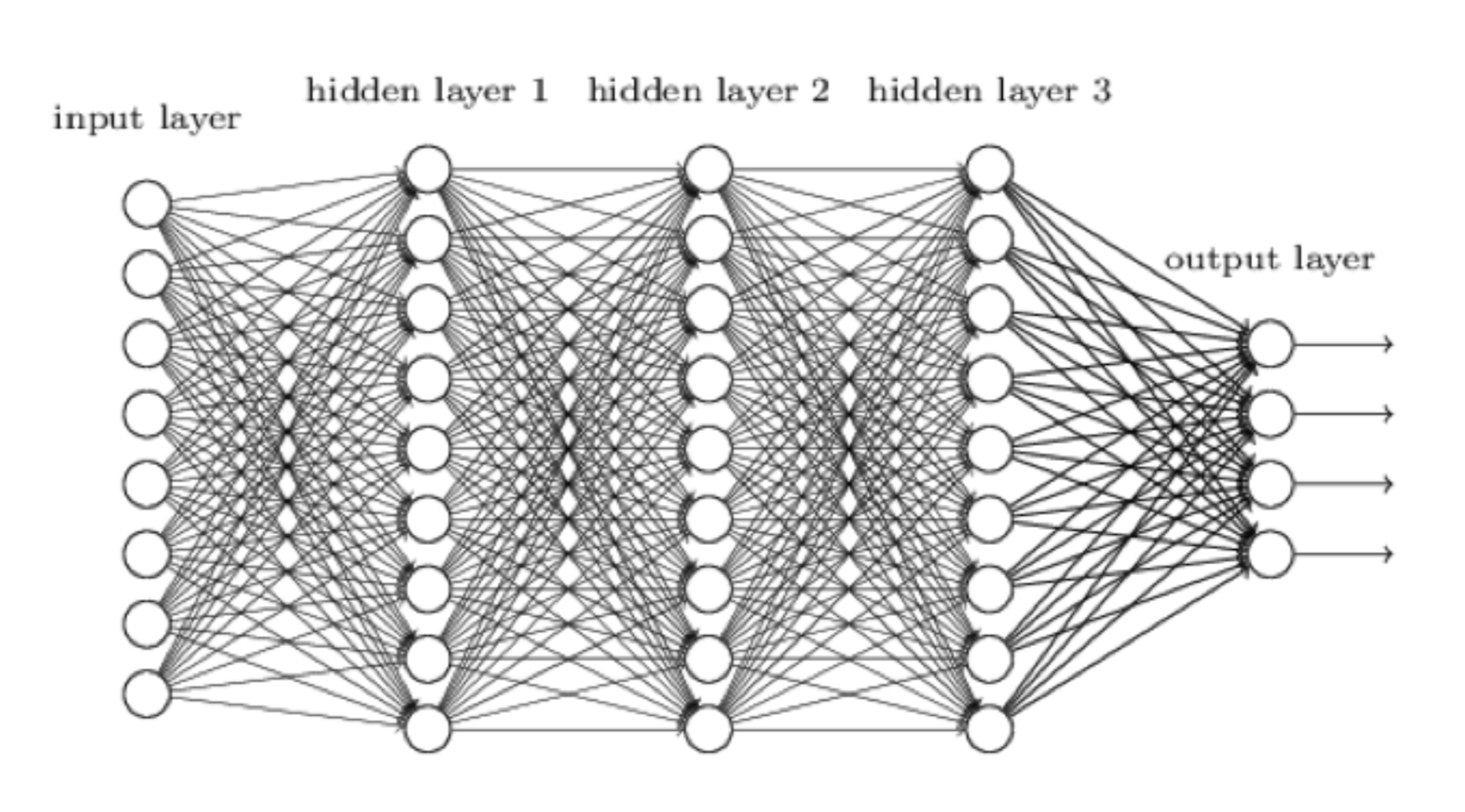
What's Inside AlphaZero's Chess Brain?
de
por adulto (o preço varia de acordo com o tamanho do grupo)







