Policy or Value ? Loss Function and Playing Strength in AlphaZero
Por um escritor misterioso
Descrição
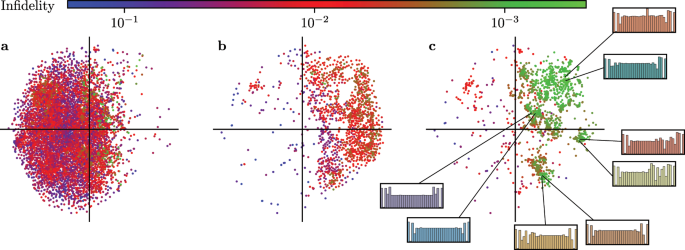
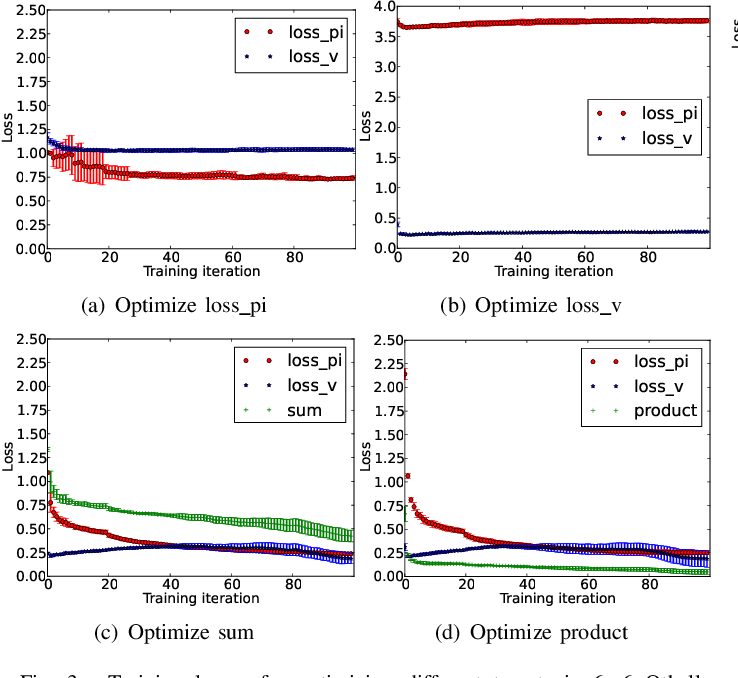
Results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Recently, AlphaZero has achieved outstanding performance in playing Go, Chess, and Shogi. Players in AlphaZero consist of a combination of Monte Carlo Tree Search and a Deep Q-network, that is trained using self-play. The unified Deep Q-network has a policy-head and a value-head. In AlphaZero, during training, the optimization minimizes the sum of the policy loss and the value loss. However, it is not clear if and under which circumstances other formulations of the objective function are better. Therefore, in this paper, we perform experiments with combinations of these two optimization targets. Self-play is a computationally intensive method. By using small games, we are able to perform multiple test cases. We use a light-weight open source reimplementation of AlphaZero on two different games. We investigate optimizing the two targets independently, and also try different combinations (sum and product). Our results indicate that, at least for relatively simple games such as 6x6 Othello and Connect Four, optimizing the sum, as AlphaZero does, performs consistently worse than other objectives, in particular by optimizing only the value loss. Moreover, we find that care must be taken in computing the playing strength. Tournament Elo ratings differ from training Elo ratings—training Elo ratings, though cheap to compute and frequently reported, can be misleading and may lead to bias. It is currently not clear how these results transfer to more complex games and if there is a phase transition between our setting and the AlphaZero application to Go where the sum is seemingly the better choice.
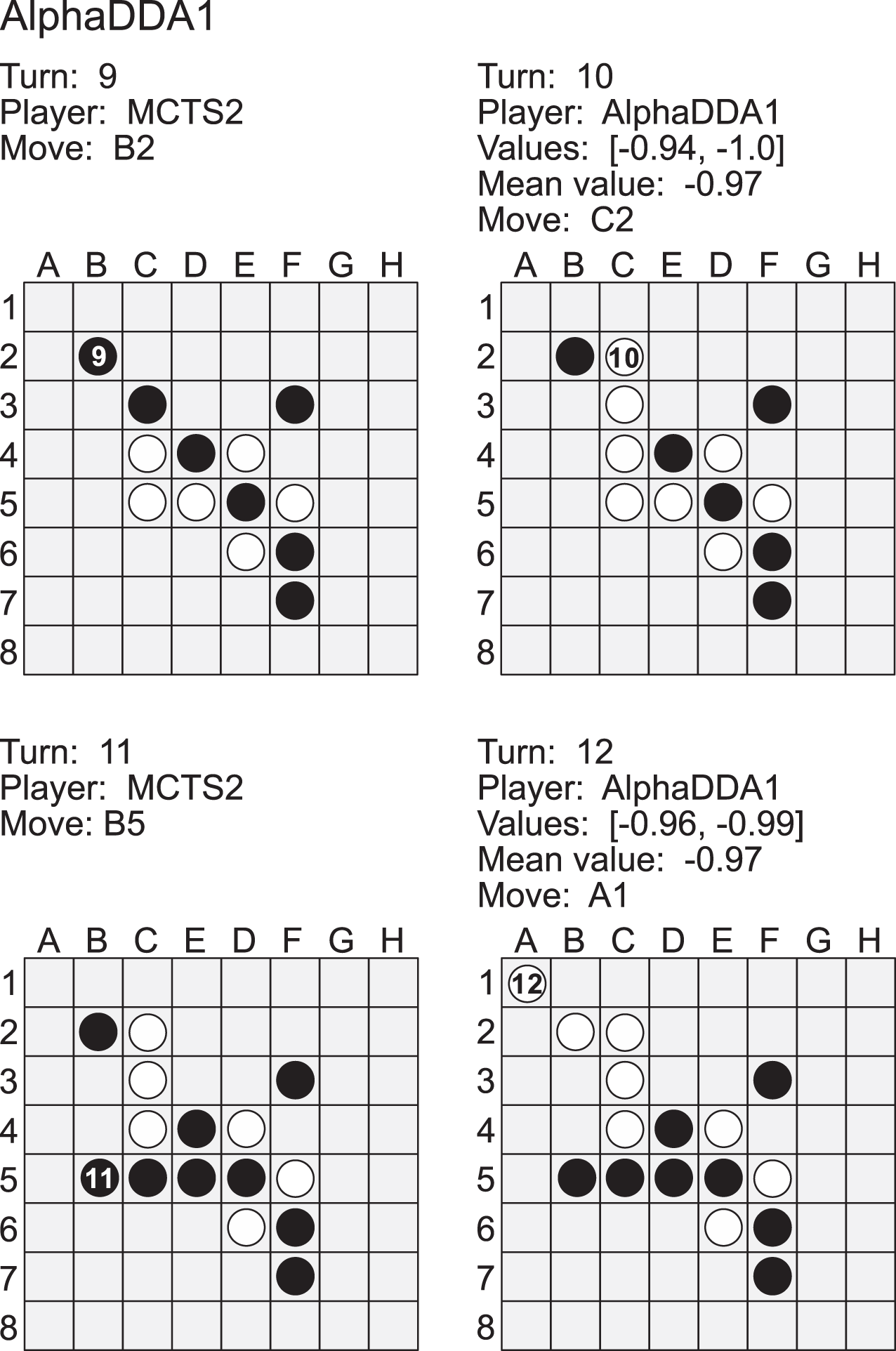
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]

Frontiers AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong
How to build your own AlphaZero AI using Python and Keras, by David Foster, Applied Data Science

Simple Alpha Zero
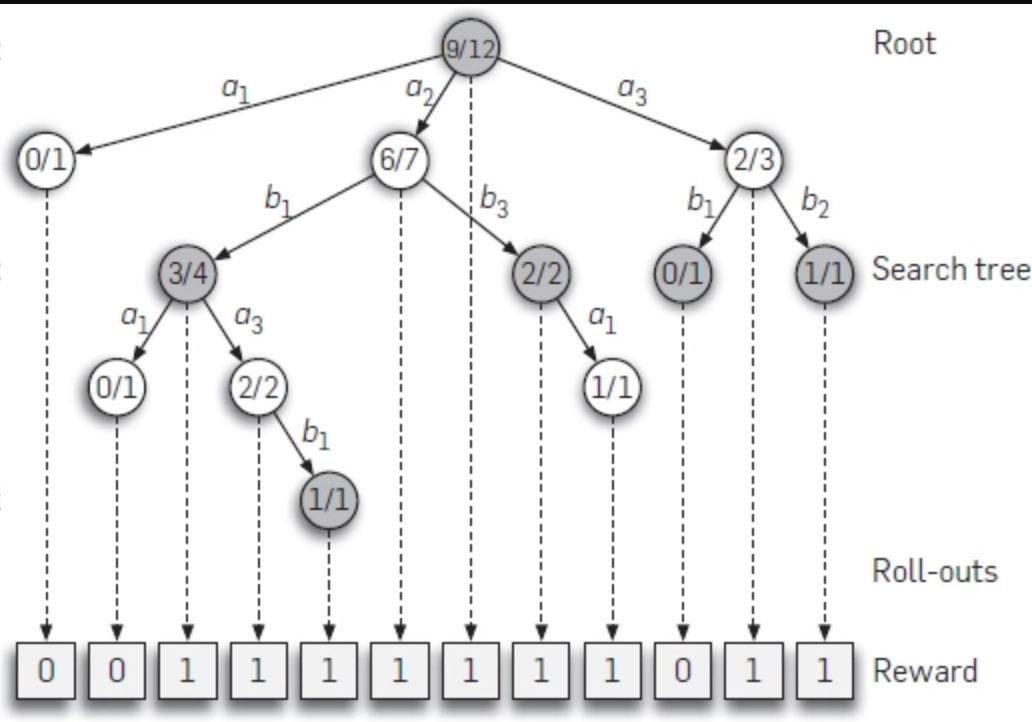
AlphaZero Explained · On AI

AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play

Multiplayer AlphaZero – arXiv Vanity

🔵 AlphaZero Plays Connect 4

AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play
Electronics, Free Full-Text

PDF) Alternative Loss Functions in AlphaZero-like Self-play
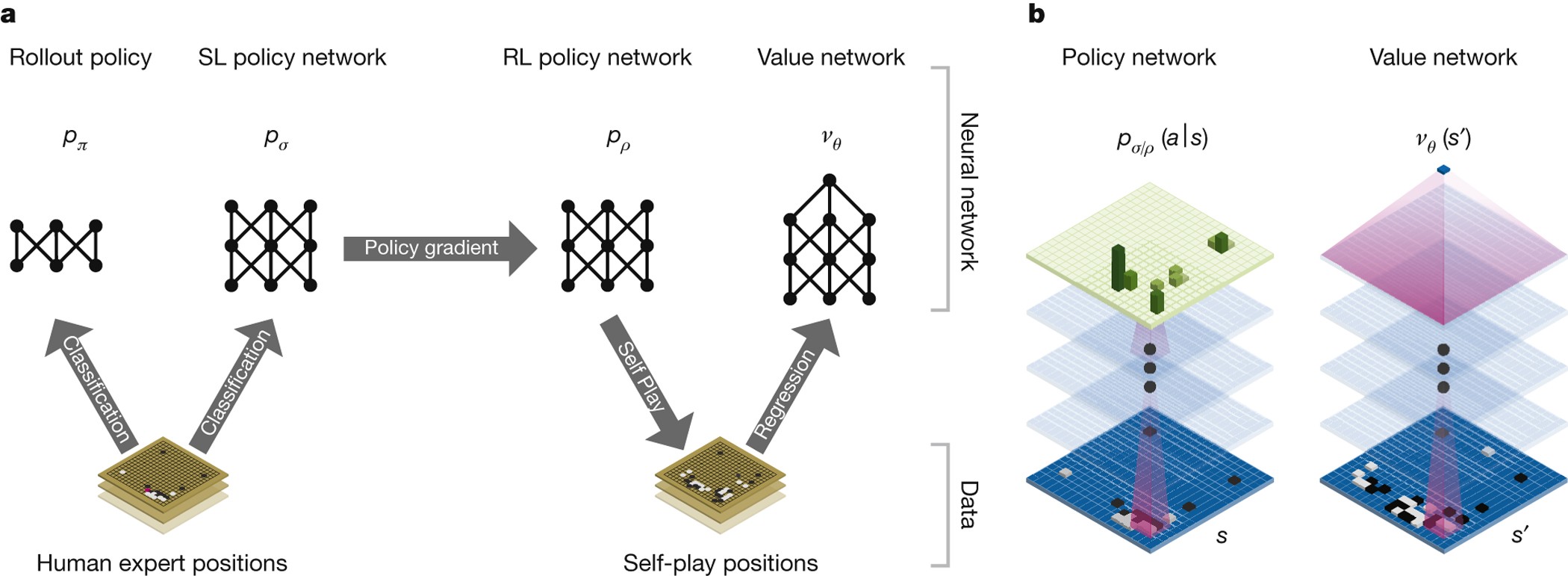
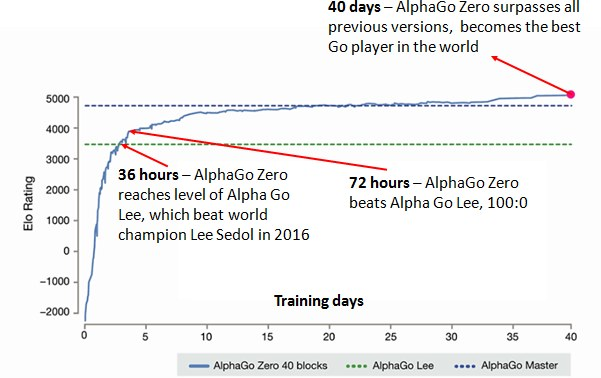
Mastering the game of Go with deep neural networks and tree search
de
por adulto (o preço varia de acordo com o tamanho do grupo)